










 분야
분야Ⅰ.
문 제
Ⅱ.
Program
1)
기본 설명
2)
주요소스 및 설명
Ⅲ.
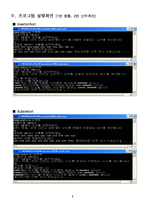
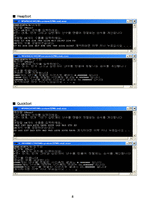
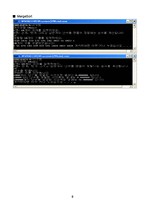
프로그램 실행화면
Ⅳ.
결 과
Ⅴ.
참고문헌 및 사이트
DATA STRUCTURE에서 데이터를 효율적으로 관리 및 사용 할 수 있도록 한다.
시스템을 구현 할 때에는 자료구조에 크게 의존하게 하며 이러하여 시스템 설계 시 어떠한
자료구조 알고리즘을 접목시키느냐에 따라 시스템의 성능이 상대적으로 나타나게 된다.
우수한 성능의 시스템을 나타낼 때 효과적이며 적절한 알고리즘의 선택은 필수이다
그 중 가장 기본적이라 할 수 있는 정렬 알고리즘에 대해 확인 할 것이다.
정렬 알고리즘이란 각종 원소들의 데이터 순서 및 조건에 따라 순서대로 열거하는 알고리즘으로
이러한 정렬 알고리즘은 데이터의 정규화나 의미 있는 결과물을 생성하는데 효과적이다.
이와 같이 정렬 알고리즘을 C프로그래밍으로 구현하려고 한다.
문제를 해결하면서 프로그래밍 코딩 능력을 지향하는데 목적이 있으며, 더 나아가 이러한
알고리즘의 흐름을 확인하며 상대적인 처리능력도 확인 할 수 있다.
총 5개의 정렬 알고리즘(Insertion, Bubble, Heap, Quick, Merge)을 구현함으로써 상대적인
처리능력도 확인 할 수 있다.
Ⅱ. Program
1) 기본설명
- 5개의 알고리즘은 작은 수부터 큰 수까지 오름차순으로 정렬
- 정렬시 자주 이용되는 swap의 경우는 #define으로 구현
- makeRand()으로 난수 생성 사용
- clock()으로 정렬하는 시간측정
- gets() 받아 공백단위로 strtok() 처리하여 정수 배열 저장
· 김상형『혼자연구하는 C, C++』와우북스, 2009
· 이지영『C로 배우는 쉬운 자료구조』프리렉, 2005
· 위키백과 http://ko.wikipedia.org